
Francisco Moschetti
The 'problem' with RAG.
The starting point, or the default approach for RAG systems looks something like this:
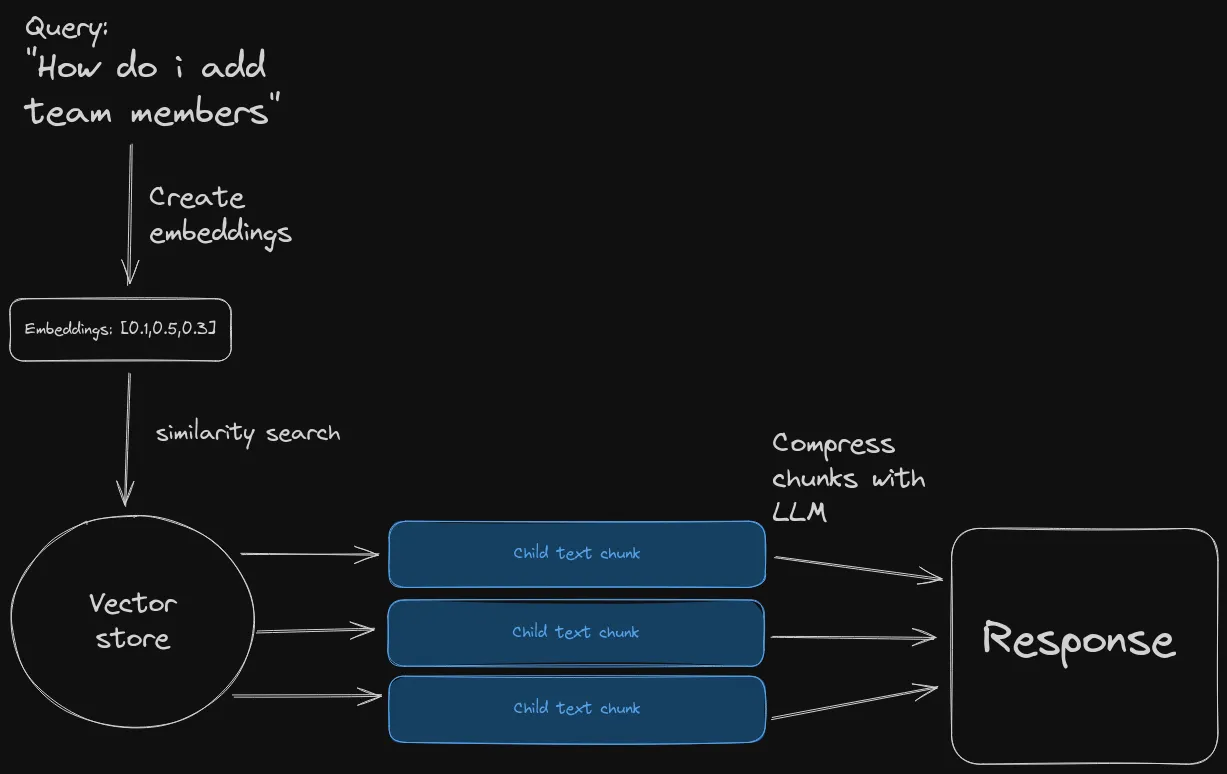
Similarity search returns relevant chunks of text from the source documents, and everything is compressed using your preferred LLM model.
If you tried this approach you know it’s not a silver bullet. What’s shown there is the starting point, you should try it, see how it performs, but it’s hard for this alone to do the trick.
And this is completly fine.
It doesn’t mean RAG is useless, it means you need to fit it to your use case.
The problem.
There is a lot of more advanced rag techniques like Self querying retrievals, Parent document retriever, Hybrid search - but the best solution is not based on how complex or advanced it is.
The best solution is the one that makes more “justice” to your data.
Last week I was testing a RAG chatbot implementation for a potential feature. And when i was looking at the knowledge base that I was going to use as my source, I realized something interesting.
Nowadays a lot of the source documentation for most things (specially SaaS products) rely a lot on media - anything from gifs to youtube videos to explain the steps required to perform a given action in the UI of a specific product.
It makes sense, we are visual creatures right? if you show me what to do, it’s going to be easier for me to undersand.
So with that understanding, it’s easy to see why sometimes the response from some users of the RAG solutions for customer support in this space is so negative.
So the problem with RAG is about not paying atention to the anatomy of your source material, ignoring how your data is composed.
The solution
So for this case in particular I realized that replying with the actual youtube video or gif that was relevant to the question, with a short and concise answer generated from the text content in the documentation was the best experience for the user
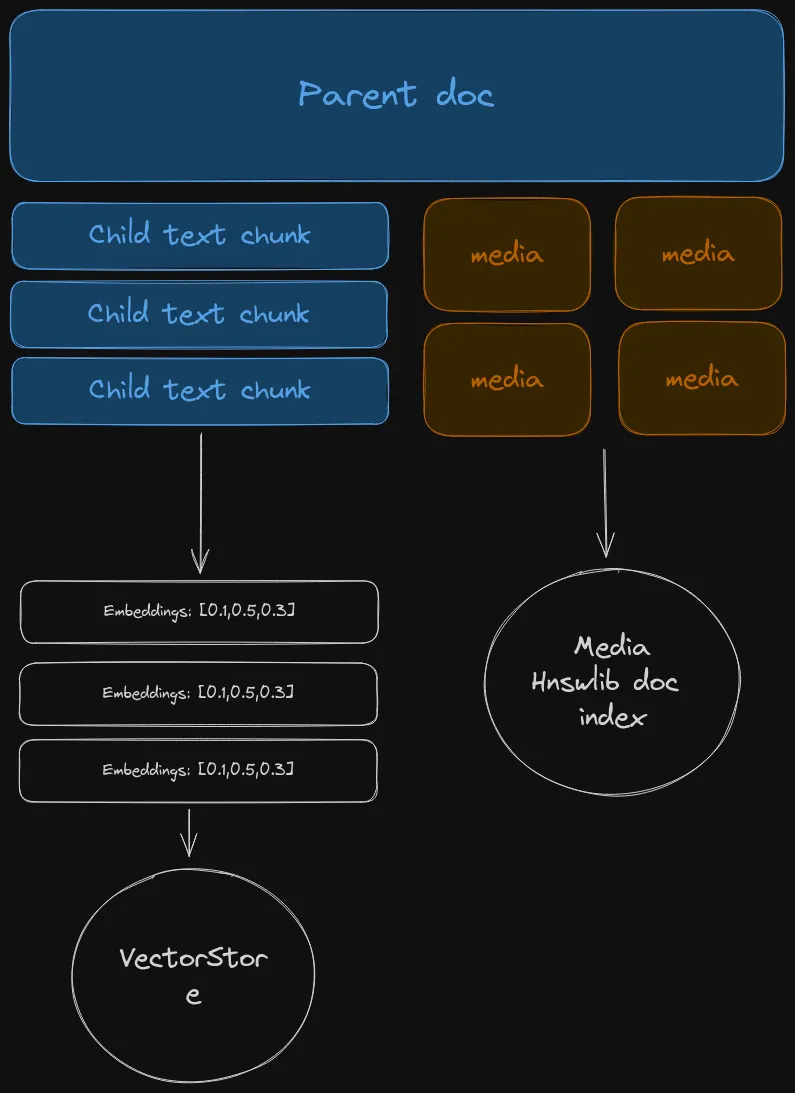
In a way, this is similar to what is known as a “parent document retrieval”.
This could be taken to another level by running the extracted media though some vision models and extend the metadata with interpretations, video transcriptions, and tags.
In order to achieve this I had to drop the default document loaders from libraries like langchain and llama-index and build my own, so I could treat each media item as a document, linked to the parent doc.
The code
So the full code for the loader might look something like this.
Please note that this is illustrative, so you will need to adjust the lookups for elements accordingly for your use case.
import uuid
import requests
from bs4 import BeautifulSoup
from langchain.schema import Document
class CustomWebLoader():
url:str
object_id:str
def __init__(self, url:str):
self.url = url
self.object_id = str(uuid.uuid4())
def _multi_media_parser(self, content: BeautifulSoup) -> [dict]:
"""
Here is where you can select the type of media you want to extract.
In the example defined below I want to only extract videos.
Args:
- Content: beautiful soup obj
Returns:
- list: list of dicts with the right structure for a langchain doc.
"""
title = content.find_all("title")[0].get_text()
video_tags = content.select("div[class^=videoPlayer]")
video_objects = [
{
"id": str(uuid.uuid4()),
"page_content": "",
"metadata": {
"source": "https://www.youtube.com/watch?v=" + video["id"],
"title": title,
"type": "video",
"parent_id": self.object_id,
},
}
for video in video_tags
]
return video_objects
def _html_parser(self, content: BeautifulSoup) -> dict:
"""
Here is where you can clean up stuff from the document.
Look at the example defined below
You probably want to do proper fallbacks for elements
like title and description.
Args:
- Content: beautiful soup obj
Returns:
- dict: A dict with the right structure for a langchain doc.
"""
#Example removing sidenav and header/nav check your doc structure.
sidenav = content.find_all("aside")
full_horizonal_nav = content.find_all("header")
decompose_list = sidenav + full_horizonal_nav
for element in decompose_list:
element.decompose()
title = content.find_all("title")[0].get_text()
description = content.find_all("meta", {"name": "description"})[0]["content"]
metadata = {
"title":title,
"description":description,
"source": self.url
}
langchain_document = {
"id": self.object_id,
"page_content": str(content.get_text()),
"metadata":metadata
}
return langchain_document
def load(self) -> dict:
response = {}
r = requests.get(self.url)
if r.status_code != 200:
raise ErrorFetchingPageContent
soup = BeautifulSoup(r.text, "html")
page_object = self._html_parser(soup)
media_objects = self._multi_media_parser(soup)
response["page"] = Document(**page_object)
response["media"] = [Document(**doc) for doc in media_objects]
return response
The order of operations is the following:
- Fetch the entire page and parse the content using BeautifulSoup.
- Create the main document object with _html_parser()
- Create the media objects with _media_parser()
- Construct the langchain documents
Now you can use that class like this
loader = CustomWebLoader(url)
loaded_data = loader.load()The result will be two sets of langchain documents, where the media elements have a metadata attribute pointing to the parent doc.
Now you can split the parent doc, create embeddings, store it in a vector database, and run similarity search on that.
But once you get your relevant chunks back, you can bring in the related media using the parent id and enrich your response.